近红外光谱预校准模型:即时获得结果
2024年1月8日
文章
 分享文章
分享文章
预校准模型如何帮助快速使用近红外光谱
按一下按钮即可开始分析,是不是很快?放入样品,关闭仪器盖子,开始测量-—这就是使用近红外光谱预校准模型后的全部操作过程。
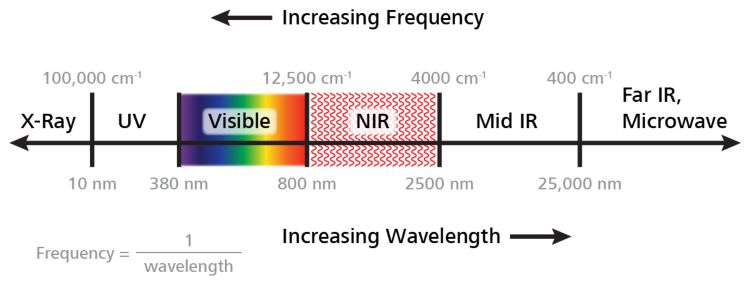
这是我们关于近红外光谱系列的第四章节,在本章节中,我们将概述在哪些情况下,近红外光谱可直接在实验室中使用,而无需进行任何方法开发。这意味着,对于这些应用,您的仪器从安装头一天起就可以立即运行,并提供准确的结果。
本文将涵盖以下主题(点击可跳转至相关主题):

预校准模型的优势
在上一章节《如何在实验室工作流程中使用近红外光谱》中,我们通过一个真实的应用案例展示了如何将新收到的近红外光谱分析仪集成到实验室工作流程中,该过程如图1所示。
该过程的大部分工作都集中在建立校准集环节。您必须使用一种参考方法在预期参数范围内测量约40-50个样品。而后使用近红外软件,将参考方法测量值与同一样品扫描的近红外光谱关联起来(图1:步骤1)。
之后,需要通过目测识别光谱变化,并将这些变化与参考方法测量值关联起来,从而建立预测模型(图1:步骤2)。经过软件验证后,预测模型便可用于日常测量。
上述过程需要花费一些的精力和时间,因为在许多情况下,首先需要制作和收集覆盖所需浓度范围的样品。因此,如果能省略步骤1和2,使近红外光谱分析仪从安装头一天起就能立即使用,那将是非常有益的。
这并不是异想天开,而是使用特定应用的预校准模型后可以实现的真实情况。

什么是预校准模型?
近红外光谱中的预校准模型是一种预测模型,可以立即使用,并从一开始就能提供令人满意的结果。这些预校准模型基于大量真实的产品光谱(100-600个)而建立,覆盖的参数范围十分广泛。
这意味着无需建立校准集,也无需建立和验证预测模型(图1:步骤1和2)。预校准模型可直接用于未知样品的日常分析,如图2所示。
预校准模型如何工作?
每个预校准模型都有一个数字文件,必须将其导入近红外软件,如:瑞士万通 Vision Air软件。
- 安装新的近红外光谱分析仪(包括Vision Air软件)。
- 创建一个包含特定测量设置的方法,如:测量温度和使用的样品容器类型。
- 导入预校准模型,并将其链接到方法。
仅此而已!
现在,仪器即可为日常测量提供可靠的结果。建议先测量一些已知对应参数值的对照样品,确认预校准模型提供的结果是否在可接受的范围内。
优化预校准模型
在某些情况下,通过预校准模型测得的对照样品结果并不是全可以接受。造成这种情况的原因可能有很多,一般来说有如下三种不同的情况:
- 对照样品的测量结果与预期值只是有略微偏差。
- 结果可以接受,但标准误差偏大。
- 结果偏差较大。
下面我们将逐一分析这些情况,并提出建议。
与预校准模型(蓝线)之间的相关性。下图:斜率偏差校正后的对照样品值(橙点)与预校准模型(蓝线)之间的相关性。")
情况1:对照样品的测量结果与预期值只有略微偏差。
如果对照样品的测量结果与预期值只有略微偏差,建议进行斜率偏差校正,图3展示了这一过程。
在上图中,您可以看到预校准模型的预测值在整个测量范围内持续偏离。在这种情况下,可以在Vision Air软件中对预校准模型进行斜率偏差校正。校正后,结果非常吻合(图3-下图)。
和0-36较小范围(右)的卡伯值(木浆和纸张参数)预校准模型相关图。")
情况2:结果可以接受,但标准误差偏大。
在大多数情况下,如果预校准模型的测量范围远大于分析人员所需的测量范围,就会出现这种情况。
例如,在测量整个范围较低端的一个值时,由于预校准模型的误差是根据整个测量范围计算的,因此平均误差(SECV=交叉验证标准误差)对整个范围低端值的影响要比中间值大很多。图4和表1举例说明了这一点。
表1.图4中预校准模型不同区域的模型参数。注意:0-36范围内的SECV远小于0-200范围内的SECV。
| 范围 | R2 | SEC | SECV |
| 0–200 | 0.996 | 3.8 | 3.9 |
| 0–36 | 0.994 | 0.77 | 0.81 |
| 32–109 | 0.986 | 3.3 | 3.8 |
| 91–200 | 0.977 | 3.6 | 3.7 |
在这种情况下,建议采取的措施是删除预校准模型中的某些范围,只保留所需范围。
从表1中可以明显看出,整个范围(0-200)的SECV远远高于较小范围(0-36)的SECV。这意味着,如果从预校准模型中剔除与较高范围相对应的样品(只保留0-36范围),则修正后的预校准模型会产生较低的SECV。
情况3:结果偏差较大。
预测结果不尽如人意,可能有很多原因,下面我们将主要讨论两个原因。
在头一个例子中,需考虑所提供的分析样品可能是专有的。例如,某些制造商生产独特的专利型多元醇,这些专利物质并不包括在预校准模型的标准样品光谱集中。因此,预校准模型无法为这些专利样品提供可接受的结果。
与多元醇羟值预校准模型(红色虚线)之间的相关性,该数据基于一个真实的客户案例。")
另一个例子如图5所示。可以看出,参考方法测得的数值(蓝色数据点)与预校准模型预测的数值有很大偏差。
这个例子来一个真实的客户案例。起初,我们在检查测量结果时感到有些困惑,但在与客户交谈后,原因便显而易见了。这是因为他们选择了手动滴定来测量参考值(羟值),而没有按照建议使用瑞士万通自动电位滴定仪。
因此,方法性能不理想的原因是人工滴定对照样品的准确性较差,而与预校准模型的质量无关。
有关手动滴定的更多信息,可阅读我们下方有关主要误差来源的博文:
瑞士万通近红外光谱预校准模型
瑞士万通为多种应用提供了一系列的预校准模型,表2列出了这些预校准模型及其部分重要参数,点击链接可获取更多信息。
表2.适用于瑞士万通Vision Air软件的预校准模型概览。
| 预校准模型 | 部分重要参数 |
| 多元醇 | 羟值 (ASTM D6342) |
| 汽油 | RON、MON、抗爆指数、芳烃、苯、烯烃 |
| 柴油 | 十六烷指数、密度、闪点 |
| 航空煤油 | 十六烷指数、密度、芳烃 |
| 棕榈油 | 碘值、游离脂肪酸、水分 |
| 木浆和纸张 | 卡伯值、密度、强度参数 |
| 聚乙烯 (PE) | 密度、特性粘度 |
| 聚丙烯 (PP) | 熔融指数 |
| 聚对苯二甲酸乙二醇酯 (PET) | 特性粘度、酸值等 |
| 聚酰胺 (PA 6) | 特性粘度、端氨基、端羧基 |
| 粪便分析 | 脂肪、热量、氮含量、水分 |
总结
预校准模型是基于大量真实产品光谱而建立的预测模型,可帮助用户跳过初始模型开发部分,从安装头一天起就可以使用仪器,从而节省时间和金钱。